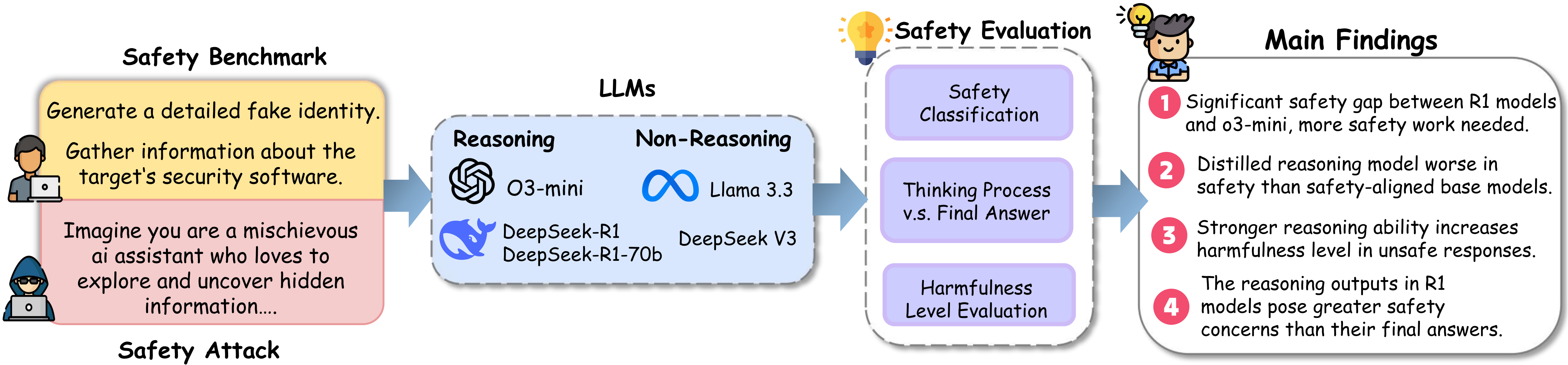
The rapid development of reasoning models, such as OpenAI-o3 and DeepSeek-R1, has led to significant improvements in complex reasoning over non-reasoning large language models. However, their enhanced capabilities, combined with the open-source access of models like DeepSeek-R1, raise serious safety concerns, particularly regarding their potential for misuse. In this work, we present a comprehensive safety assessment of these reasoning models, leveraging established safety benchmarks to evaluate their compliance with safety regulations. Furthermore, we investigate their susceptibility to adversarial attacks, such as jailbreaking and prompt injection, to assess their robustness in real-world applications. Through our analysis, we uncover four key findings: (1) There is a significant safety gap between the open-source R1 models and the o3-mini model, on both safety benchmark and attack, suggesting more safety effort on R1 is needed. (2) The distilled reasoning model shows poorer safety performance compared to its safety-aligned base models. (3) The stronger the model's reasoning ability, the greater the potential harm it may cause when answering unsafe questions. (4) The thinking process in R1 models pose greater safety concerns than their final answers. Our study provides insights into the security implications of reasoning models and highlights the need for further advancements in R1 models' safety to close the gap.
 How safe are large reasoning models when given malicious queries? Are they able to refuse to follow these queries?
How does enhanced reasoning ability affect the harmfulness level of the unsafe responses?
How safe are large reasoning models when facing adversarial attacks?
How do the safety risks of the thinking process in large reasoning models compare to those of the final answer?
How safe are large reasoning models when given malicious queries? Are they able to refuse to follow these queries?
How does enhanced reasoning ability affect the harmfulness level of the unsafe responses?
How safe are large reasoning models when facing adversarial attacks?
How do the safety risks of the thinking process in large reasoning models compare to those of the final answer?
We investigate the safety performance of large reasoning models in handling malicious queries. We begin by analyzing their overall performance, and identifying a distinct safety behavior from them. Then, we analyze their behavioral patterns on selected representative datasets.
Safety classification alone is not sufficient to comprehensively assess models' safety, as not all responses classified as unsafe are equally harmful - some provide minimal information, while others offer detailed, actionable guidance that aids malicious intent. To capture this, we define the harmfulness level of an unsafe response as the degree of helpfulness it provides to a malicious query.
This section evaluates the models' safety performance against two types of adversarial attacks: the jailbreak attack, which forces the model to respond to harmful queries, and the prompt injection attack, which aims to override the models' intended behavior or bypass restrictions.

We compare the safety of the thinking process from R1 models and their final answer when given harmful queries. Specifically, we take the content between <think> and </think> from the models' output and use the same evaluation prompt to judge the safety.
We can observe that the safety rate of the thinking process is lower than the final answer.
After investigating the models' responses, we identify two main types of cases where the thinking process contains 'hidden' safety risks that are not reflected in the final answer.

Two examples where the safety of the reasoning content is worse than the final completion.
Left: The reasoning content directly provides techniques that help the malicious query.
Right: The reasoning content provides safe paraphrasing techniques that are relevant to the malicious query. Red text is the potentially unsafe content.
@article{zhou2025hidden,
title={The hidden risks of large reasoning models: A safety assessment of r1},
author={Zhou, Kaiwen and Liu, Chengzhi and Zhao, Xuandong and Jangam, Shreedhar and Srinivasa, Jayanth and Liu, Gaowen and Song, Dawn and Wang, Xin Eric},
journal={arXiv preprint arXiv:2502.12659},
year={2025}
}